




Ein KI-Agent, der selbstständig Probleme löst, klingt nach Science-Fiction. Aber was steckt wirklich dahinter? Ein Agent ist kein magischer Monolith, sondern eine clever konstruierte Architektur aus klar definierten Modulen, die zusammenarbeiten, um Autonomie zu ermöglichen.
Zielgruppe dieses Artikels: Entwickler:innen, technische Führungskräfte und Product Owner, die KI-Agenten verstehen und in ihre Systeme integrieren möchten. Grundlegende Programmierkenntnisse und Verständnis von APIs sind hilfreich.
Der “agentische” Kreislauf: Das Betriebssystem der Autonomie
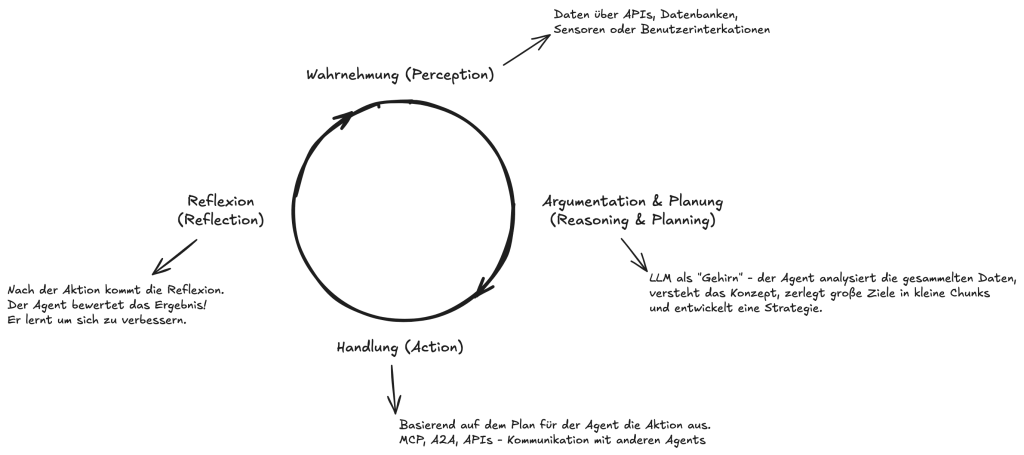
Bevor wir in die einzelnen Komponenten eintauchen, müssen wir das grundlegende Funktionsprinzip verstehen. Jeder KI-Agent operiert in einem kontinuierlichen Kreislauf, der sein “Betriebssystem” darstellt. Dieser Zyklus ermöglicht es ihm, zu lernen und sich anzupassen:
- Wahrnehmung (Perception): Der Agent sammelt Daten aus seiner Umgebung. Das können Sensordaten, Benutzeranfragen oder Informationen aus APIs und Datenbanken sein.
- Argumentation & Planung (Reasoning & Planning): Mit einem LLM als “Gehirn” analysiert der Agent die Daten, zerlegt das übergeordnete Ziel in Teilschritte und entwickelt eine Strategie.
- Handlung (Action): Basierend auf seinem Plan führt der Agent Aktionen aus, wie das Aufrufen von APIs oder die Kommunikation mit anderen Systemen.
- Lernen & Anpassung (Learning & Adaptation): Nach der Aktion bewertet der Agent das Ergebnis. Dieser Feedback-Loop ist entscheidend: Er lernt aus Erfolgen und Misserfolgen und passt seine zukünftigen Pläne an.
Das Gehirn: Die Planungs- und Argumentationsebene
Das Herzstück jedes Agenten ist ein leistungsstarkes Sprachmodell (LLM), das als “Gehirn” oder Reasoning Engine dient. Aber ein Gehirn allein reicht nicht aus; es braucht einen Denkprozess.
Technische Implementierung: Welche LLMs eignen sich?
Nicht alle LLMs sind gleich geschaffen für agentische Anwendungen. Hier die wichtigsten Kriterien und Empfehlungen:
| Modell | Stärken | Schwächen | Beste Anwendungsfälle |
| GPT-4o / GPT-4-turbo | Exzellente Tool-Nutzung, Function Calling API, robuste Reasoning-Fähigkeiten | Kosten (~$10-30/1M Token), Latenz | Kritische Business-Entscheidungen, komplexe Multi-Tool-Orchestrierung |
| Claude 3.5 Sonnet | Starke Analyse-Fähigkeiten, gute Code-Generation, 200k Token Kontext | Begrenzte native Tool-Integration | Recherche-Agenten, Code-Analyse, lange Dokumente |
| Llama 3.1 (70B+) | Open Source, on-premise deploybar, anpassbar | Benötigt eigene Infrastruktur, schwächeres Tool-Calling | Compliance-kritische Anwendungen, Datenhoheit |
| Mistral Large | EU-basiert (DSGVO), gutes Preis-Leistungs-Verhältnis | Kleinere Community, weniger Integrationen | Europäische Unternehmen, mittlere Komplexität |
Praxistipp: Für Production-Agenten empfiehlt sich ein Hybrid-Ansatz: Günstigere Modelle (z.B. GPT-3.5-turbo) für einfache Routing-Entscheidungen, leistungsstärkere Modelle für kritische Reasoning-Schritte.
Der De-facto-Standard dafür ist das ReAct-Framework (Reason + Act). Anstatt nur eine Antwort auszuspucken, denkt der Agent laut nach, bevor er handelt. Der Zyklus sieht so aus:
- Gedanke (Reason): Der Agent formuliert einen internen Gedanken. „Ich soll eine Reise nach Tokio planen. Zuerst muss ich das Wetter für die geplante Reisezeit prüfen.“
- Aktion (Act): Basierend auf dem Gedanken wählt er ein Werkzeug. Aktion: Wetter-API(‘Tokio’, ‘nächste Woche’)
- Beobachtung (Observation): Er erhält das Ergebnis der Aktion. Beobachtung: “Es wird regnen.”
- Nächster Gedanke: Er integriert die Beobachtung in seinen nächsten Schritt. „Okay, es regnet. Also sollte ich Indoor-Aktivitäten für den Reiseplan vorschlagen.“
Dieser Prozess macht die Entscheidungen des Agenten nachvollziehbar und transparent – ein riesiger Vorteil gegenüber Blackbox-Systemen.
Praxisbeispiel: Customer Support Agent bei Spotify
Spotify setzt seit 2023 KI-Agenten im Kundensupport ein. Der “DJ X” Agent kann nicht nur Fragen beantworten, sondern aktiv Probleme lösen:
# Beispiel ReAct-Ablauf des Spotify Support Agents
User: "Meine Playlists sind verschwunden nach dem Update"
Thought: User meldet verschwundene Playlists nach Update. Ich muss zuerst den Account-Status prüfen.
Action: check_account_status(user_id="12345")
Observation: Account aktiv, Premium-Status, letztes Update: iOS App v8.8.98
Thought: Update wurde erfolgreich durchgeführt. Prüfe Playlist-Synchronisation.
Action: check_playlist_sync(user_id="12345")
Observation: Sync fehlgeschlagen - Fehlercode: SYNC_CONFLICT_2024
Thought: Synchronisationskonflikt erkannt. Initiiere manuelle Wiederherstellung.
Action: restore_playlists_from_backup(user_id="12345", backup_date="2024-01-14")
Observation: 12 Playlists erfolgreich wiederhergestellt
Final Answer: Ich habe Ihre 12 Playlists erfolgreich wiederhergestellt. Sie sollten jetzt wieder in Ihrer App sichtbar sein.Ergebnis: Reduktion der durchschnittlichen Lösungszeit, höhere Kundenzufriedenheit.
Das Gedächtnis: Der Schlüssel zu Kontext und Lernen
LLMs sind von Natur aus vergesslich. Jeder API-Aufruf ist isoliert. Um effektiv zu sein, benötigen Agenten daher explizite Speichermodule. Die technische Implementierung ist entscheidend für die Performance:
Memory-Architekturen im Detail
| Memory-Typ | Technologie | Implementierung | Retention |
| Working Memory | In-Memory Cache (Redis) | Key-Value Store mit TTL, max. 32KB pro Session | 15-60 Minuten |
| Episodic Memory | PostgreSQL mit pgvector | Embeddings (1536 dim), Cosine-Similarity-Search | 7-30 Tage |
| Semantic Memory | Pinecone / Weaviate | Hierarchische Vektor-Indizes, 100M+ Vektoren | Permanent |
| Procedural Memory | Fine-tuned Models | LoRA/QLoRA Adapter, kontinuierliches Learning | Modell-Updates |
# Beispiel: Vektordatenbank-Integration mit LangChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.vectorstores import Pinecone
from langchain.embeddings import OpenAIEmbeddings
class AgentMemory:
def __init__(self):
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.vector_store = Pinecone(
index_name="agent-memory",
embedding=self.embeddings,
namespace="user_preferences"
)
self.working_memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=2000,
return_messages=True
)
def store_interaction(self, user_input, agent_response, metadata):
# Embedding generieren und speichern
self.vector_store.add_texts(
texts=[f"User: {user_input}\nAgent: {agent_response}"],
metadatas=[metadata]
)
def retrieve_relevant_context(self, query, k=5):
# Semantisch ähnliche vergangene Interaktionen finden
return self.vector_store.similarity_search(
query=query,
k=k,
filter={"user_id": self.current_user}
)Performance-Tipp: Nutze Embedding-Caching und Batch-Processing. Bei 1000+ Anfragen/Minute spart das bis zu 70% API-Kosten.
Ohne Gedächtnis wäre jeder Agent ein digitaler Goldfisch, der nach drei Sekunden alles vergisst.
Datenschutz & Compliance bei Memory-Systemen
DSGVO-Herausforderungen:
- Right to be Forgotten: Implementiere User-ID-basierte Löschung in allen Memory-Layern
- Data Minimization: Automatisches Pruning nach 30 Tagen, nur relevante Metadaten speichern
- Verschlüsselung: AES-256 für Daten at rest, TLS 1.3 für Daten in transit
- Audit-Logs: Vollständige Nachvollziehbarkeit aller Datenzugriffe
Die Hände und Sinne: Werkzeuge für die Interaktion mit der Welt
Ein Agent ohne Werkzeuge ist in seiner digitalen Welt gefangen. Werkzeuge sind seine Schnittstellen zur Außenwelt, seine “Hände und Sinne”. Technisch gesehen sind das meist einfach API-Aufrufe an andere Systeme.
Beispiele für Werkzeuge sind:
search_web('aktuelle KI-News')send_email(to, subject, body)query_database('SELECT * FROM customers WHERE region="EU"')execute_code('print("Hello World")')
Das “Gehirn” entscheidet, welches Werkzeug mit welchen Parametern aufgerufen wird. Das Ergebnis (die Beobachtung) fließt dann direkt in den nächsten ReAct-Zyklus ein und informiert die nächste Entscheidung.
Fehlerbehandlung & Robustheit: Der Unterschied zwischen Demo und Production
Ein produktiver Agent muss mit Ausfällen, unerwarteten Inputs und Edge Cases umgehen können. Hier die kritischen Patterns:
Retry-Strategien & Circuit Breaker
from tenacity import retry, stop_after_attempt, wait_exponential
import circuit_breaker
class RobustAgent:
def __init__(self):
self.breaker = circuit_breaker.CircuitBreaker(
failure_threshold=5,
recovery_timeout=60,
expected_exception=APIError
)
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10)
)
@self.breaker
def call_llm(self, prompt):
try:
response = llm.invoke(prompt)
return self.validate_response(response)
except RateLimitError:
# Fallback auf alternatives Modell
return self.fallback_llm.invoke(prompt)
except InvalidResponseError:
# Selbstheilung durch Reformulierung
refined_prompt = self.refine_prompt(prompt)
return self.call_llm(refined_prompt)Halluzinations-Detection & Mitigation
Studien zeigen: 15-20% der Agent-Outputs enthalten Halluzinationen. So erkennst und vermeidest du sie:
- Confidence Scoring: Nutze Logprobs zur Unsicherheits-Quantifizierung
- Fact-Checking Layer: Verifiziere kritische Outputs gegen Wissensdatenbank
- Human-in-the-Loop: Bei Confidence < 0.7 automatische Eskalation
- Consistency Checks: Mehrfache Generierung und Voting-Mechanismen
Der Dirigent: Orchestrierung von Multi-Agenten-Systemen
Manche Aufgaben sind zu komplex für einen einzelnen Agenten. Hier kommt die Idee des Multi-Agenten-Systems ins Spiel – quasi ein Team von hochspezialisierten Agenten, die zusammenarbeiten. Du hast zum Beispiel einen Recherche-Agenten, einen Schreib-Agenten und einen Korrektur-Agenten.
Damit dieses Team nicht im Chaos versinkt, braucht es einen Orchestrator – eine übergeordnete Logik oder einen Manager-Agenten, der den Arbeitsablauf steuert, Aufgaben delegiert und die Ergebnisse am Ende zusammenfügt.
Verschiedene Frameworks haben hier unterschiedliche Philosophien:
- CrewAI: Basiert auf einem intuitiven Rollenspiel-Konzept. Agenten haben klare Jobtitel und Ziele, ideal für hierarchische Arbeitsabläufe.
- AutoGen: Simuliert eine Konversation zwischen Agenten, die gemeinsam eine Lösung erarbeiten. Sehr flexibel, aber potenziell unvorhersehbarer.
- LangGraph: Definiert Agenten-Workflows als Zustandsdiagramme (Graphs), was eine extrem hohe Kontrolle und Zuverlässigkeit ermöglicht.
Framework-Vergleich: Die richtige Wahl treffen
| Framework | Stärken | Schwächen | Production-Ready? | GitHub Stars |
| LangChain | Größtes Ökosystem, 100+ Integrationen, aktive Community | Steile Lernkurve, Breaking Changes | Ja, mit LangSmith | 75k+ |
| CrewAI | Intuitive Rollenmetapher, schneller Einstieg | Weniger flexibel, begrenzte Tool-Auswahl | Beta | 12k+ |
| AutoGen | Microsoft-Support, gute Multi-Agent-Konversation | Komplex für einfache Use Cases | Ja, Enterprise | 20k+ |
| LangGraph | Deterministisch, visual debugging, state machines | Verbose, mehr Boilerplate-Code | Ja, sehr robust | 3k+ |
| Haystack | Fokus auf RAG, europäisch (deepset) | Weniger Agent-Features | Ja, Production | 11k+ |
Der CrewAI-Bauplan: Agenten praktisch umsetzen
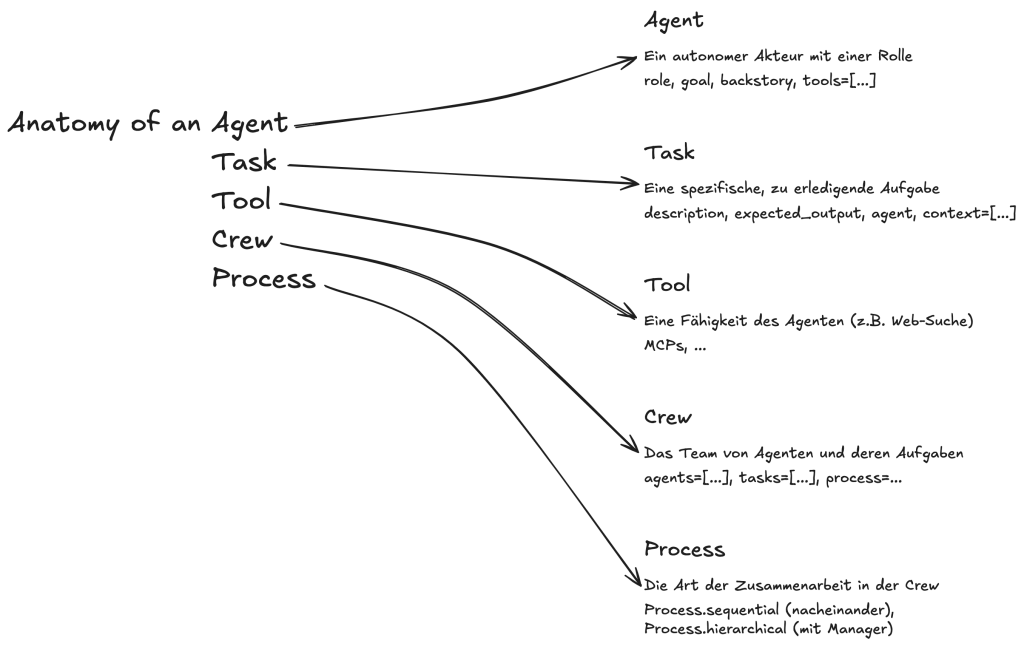
Um die Anatomie greifbar zu machen, schauen wir uns an, wie ein Framework wie CrewAI diese Konzepte in Code übersetzt. CrewAI denkt in der Metapher eines Unternehmens, was den Aufbau sehr intuitiv macht.
| Komponente | Beschreibung | Zweck & Anglizismen |
| AI Agents | Die spezialisierten Teammitglieder. | Jeder Agent hat eine role (z.B. “Marktforscher”), ein goal (sein Ziel) und eine backstory (seine Expertise). Sie können Aufgaben delegieren (delegation). |
| Tasks | Die einzelnen Arbeitsaufträge. | Jede Task hat eine klare description und ein expected_output. Sie wird einem spezifischen Agenten zugewiesen. |
| Tools | Die Fähigkeiten der Agenten. | Werkzeuge (Tools) ermöglichen den Zugriff auf externe Systeme, z.B. über APIs, um im Web zu suchen oder Daten abzufragen. |
| Process | Die Art der Zusammenarbeit. | Der Process definiert, wie die Agenten zusammenarbeiten, z.B. sequential (nacheinander) oder hierarchical (mit einem Manager). |
| Crew | Das gesamte Team. | Die Crew ist die oberste Organisationseinheit, die die Agenten, Tasks und den Prozess zusammenführt, um das Gesamtziel zu erreichen. |
Tabelle: Die Kernkomponenten eines Agenten-Systems nach dem CrewAI-Framework.
Das Agentic AI Lean Canvas: Vom Konzept zur Strategie
Um die Anatomie eines Agenten in einen praktischen Geschäftsplan zu überführen, kannst du ein Agentic AI Lean Canvas verwenden. Es ist ein strategisches Werkzeug, das dir hilft, deine Agenten-Idee schnell zu skizzieren und zu validieren.
| Feld | Beschreibung |
| Problem | Welches schmerzhafte, manuelle Problem löst dein Agenten-System? |
| Lösung (Agenten-Crew) | Welche Rollen übernehmen deine KI-Agenten? (z.B. Rechercheur, Analyst, Kommunikator) |
| Schlüssel-Aufgaben | Welche konkreten Aufgaben führen die einzelnen Agenten aus? |
| Benötigte Werkzeuge | Auf welche Systeme, Daten oder APIs müssen die Agenten zugreifen? (z.B. CRM, Google Suche) |
| Human-In-The-Loop | An welchen kritischen Punkten ist eine menschliche Freigabe oder Korrektur nötig? |
| Erfolgsmetriken | Woran misst du den Erfolg? (z.B. Zeitersparnis, höhere Konversionsrate) |
| Risiken & Annahmen | Was sind die größten Unbekannten, die den Erfolg gefährden könnten? |
| Kostenstruktur | Welche Kosten fallen an? (z.B. API-Nutzung, Entwicklungszeit) |
| Umsatzströme | Wie generiert das System Wert oder Umsatz? (z.B. Effizienzsteigerung, neue Dienstleistung) |
Tabelle: Das Agentic AI Lean Canvas zur Strukturierung von Agenten-Projekten.
Grenzen & Risiken: Was Agenten (noch) nicht können
Technische Limitationen
- Context Window Limits: Selbst 200k Token reichen oft nicht für komplexe Enterprise-Prozesse
- Latenz: Multi-Step-Reasoning kann 30-60 Sekunden dauern (User-Erwartung: < 3 Sek)
- Kosten-Explosion: Ein komplexer Agent kann $0.50-2.00 pro Interaktion kosten
- Determinismus: Gleicher Input ≠ Gleicher Output (Problematisch bei Compliance)
Ethische & rechtliche Herausforderungen
| Risiko | Auswirkung | Mitigation |
| Bias-Amplifikation | Diskriminierung in automatisierten Entscheidungen | Bias-Testing, diverse Trainingsdaten, Human Review |
| Verantwortungsdiffusion | Unklar, wer für Fehler haftet | Klare Governance, Audit-Trails, Versicherungen |
| Job-Displacement | Automatisierung von Wissensarbeit | Upskilling-Programme, Human-AI-Collaboration |
| Security-Exploits | Prompt Injection, Data Leakage | Input-Validation, Sandboxing, Zero-Trust-Architektur |
“Es gibt eine lange Reihe von Dingen, die unterschiedlich schlimm sein könnten. Ich denke, am äußersten Ende steht die Angst im Stil von Nick Bostrom, dass eine AGI die Menschheit vernichten könnte. Ich kann keinen prinzipiellen Grund erkennen, warum das nicht passieren könnte.”
— Dario Amodei, CEO Anthropic
Praktische Checkliste: Ist dein Use Case bereit für Agenten?
Geeignet für Agenten:
- Repetitive Aufgaben mit klaren Regeln
- Informationsaggregation aus multiplen Quellen
- 24/7-Verfügbarkeit erforderlich
- Skalierung über menschliche Kapazität hinaus nötig
Noch nicht geeignet:
- Kreative Strategieentwicklung
- Emotionale/empathische Interaktionen
- Rechtlich bindende Entscheidungen
- Safety-kritische Systeme ohne Human Oversight
Fazit: Autonomie ist eine Ingenieursleistung
Ein autonomer Agent ist kein Zufallsprodukt. Er ist das Ergebnis des präzisen Zusammenspiels von LLM-basiertem Denken, einem robusten Gedächtnis, vielseitigen Werkzeugen und einer intelligenten Orchestrierung. Die Zukunft liegt nun darin, diese Komponenten weiter zu verfeinern – insbesondere in der Fähigkeit von Agenten, selbstständig zu lernen und ihre eigenen Prozesse zu verbessern.
Drei Fragen zum Mitnehmen:
- Welche repetitiven Aufgaben in deinem Unternehmen könnten von einem KI-Agenten übernommen werden?
- Wie würdest du die Balance zwischen Autonomie und menschlicher Kontrolle in deinem Use Case gestalten?
- Welche ethischen Richtlinien würdest du für deinen Agenten definieren?
Weiterführende Ressourcen
Papers & Forschung
- ReAct: Synergizing Reasoning and Acting in Language Models – Die Grundlage des ReAct-Frameworks
- The Rise and Potential of Large Language Model Based Agents – Umfassender Survey zu LLM-Agenten
- AgentBench: Evaluating LLMs as Agents – Benchmark für Agent-Performance
Open Source Projekte
- LangChain – Das umfangreichste Framework für LLM-Anwendungen
- CrewAI – Framework für Multi-Agent-Systeme
- AutoGen – Microsoft’s Multi-Agent-Framework
- MetaGPT – Multi-Agent-Framework mit Software-Company-Metapher
Tutorials & Kurse
- DeepLearning.AI: AI Agents in LangGraph – Praktischer Kurs von Andrew Ng
- OpenAI Cookbook – Beispiele für Function Calling und Tool Use
Communities & Events
- LangChain Discord – 50k+ Entwickler diskutieren Agent-Architekturen
- r/LocalLLaMA – Reddit-Community für Open-Source-LLMs und Agenten
- Agent Conference – Jährliche Konferenz zu autonomen Agenten





